容器中进程启动的两种模式
docker容器内运行的进程全部都是宿主机上的独立进程;该进程是不是docker容器进程本身要依据Dockerfile的写法判定。
1 | 在ENTRYPOINT和CMD指令中,提供了两种不同的进程执行方式:shell和exec |
- 创建dockerfile 启动验证
1
2
3
4
5
6
7# shell方式
# 制作镜像docker build -t myshellredis -f shellredis/dockerfile .
# 运行 docker run -d --name myshellredis shellredis
FROM ubuntu:14.04
RUN apt-get update && apt-get install redis-server -y && rm -rf /var/lib/apt/lists/*
EXPOSE 6379
CMD "/usr/bin/redis-server"

1 | # exec方式 |

- 启动总结
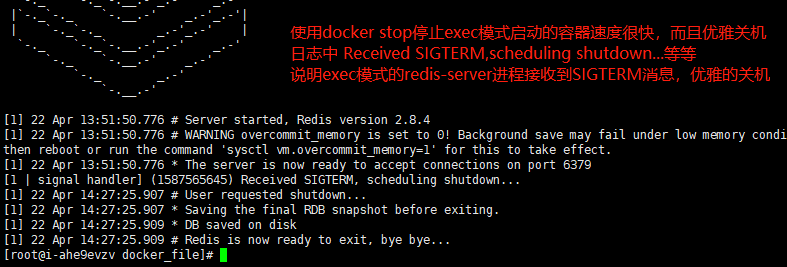
1 | 由此可看出,execredis镜像中以exec方式启动容器中的redis进程,所以redis进程就是容器进程本身。 |
- 停止容器
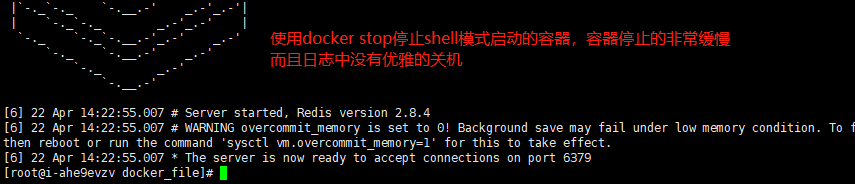
1 | Docker提供了docker stop和docker kill两个命令向容器中的1号进程发送信号。 |
- 总结
1 | 原因在于,用shell脚本启动的容器,其1号进程是shell进程。shell进程中没有对SIGTERM信号的处理逻辑,所以它忽略了接收到的SIGTERM信号。 |
容器中的”隔离”
1 | 每个容器内部的PID和进程体系都是相互隔离、互不影响的。 |
容器的本质
简单的给容器下个定论:容器 = CGroups + Namespace + Rootfs
- Namespace
1 | namespace是linux提供的一种内核级别的环境隔离方法,提供了对Mount、UTS、IPC、PID、Network、User等进行隔离的机制。 |
容器技术原理
chroot
1
2
3chroot 是在Unix和Linux系统的一个操作,针对正在运作的软件行程和它的子进程,改变它外显的根目录。
chroot虽然实现了当前进程与主机的隔离,但是网络信息、进程信息等并未隔离。
还需要Namespace、Cgroups和联合文件系统来实现完整的容器。Namespace
1
2Namespace 是 Linux 内核的一项功能,该功能对内核资源进行隔离,使得容器中的进程都可以在单独的命名空间中运行,并且只可以访问当前容器命名空间的资源。
Namespace 可以隔离进程 ID、主机名、用户 ID、文件名、网络访问和进程间通信等相关资源。Cgroups
1
2Cgroups 是一种 Linux 内核功能,可以限制和隔离进程的资源使用情况(CPU、内存、磁盘 I/O、网络等)。
在容器的实现中,Cgroups 通常用来限制容器的 CPU 和内存等资源的使用。联合文件系统
1
2联合文件系统,又叫 UnionFS,是一种通过创建文件层进程操作的文件系统,因此,联合文件系统非常轻快。
Docker 使用联合文件系统为容器提供构建层,使得容器可以实现写时复制以及镜像的分层构建和存储。
```

