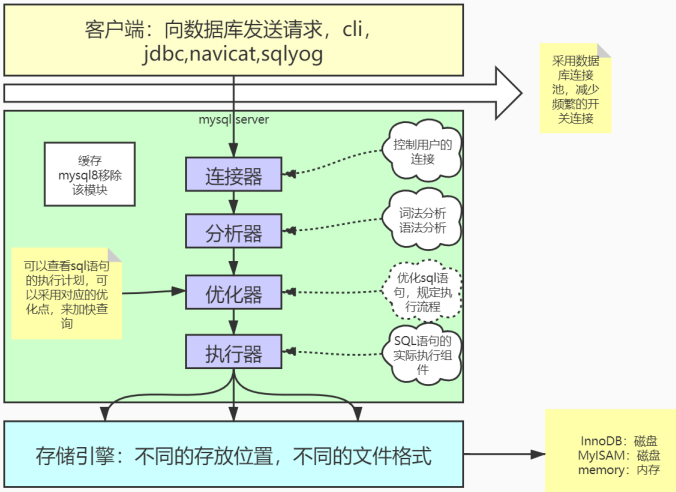
Mysql架构
1 | 不同的存储引擎,数据文件和索引文件存放的位置是不同的,因此有了分类: |
InnoDB与MyISAM存储引擎区别
- 两者主要特点
1 | InnoDB:行级锁、事务安全(ACID)、支持外键。InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全存储引擎。 |
1 | MyISAM:表级锁、不支持事务和全文索引。 |
两者性能厕所
1
2随着CPU核数的增加,InnoDB的吞吐量反而越好,而MyISAM,其吞吐量几乎没有什么变化.
显然,MyISAM的表锁定机制降低了读和写的吞吐量。事务支持与否
1
2InnoDB是事务安全的;
事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而MyISAM就不可以了。
1 | MyISAM是一种非事务性的引擎,使得MyISAM引擎的MySQL可以提供高速存储和检索,以及全文搜索能力。 |
- 两者构成上的区别
1
2
3
4数据和文件在一起(InnoDB)
.frm:存放的是表结构
.ibd:存放数据文件和索引文件
基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的大小只受限于操作系统文件的大小,一般为2GB。
1 | 每个MyISAM在磁盘上存储成三个文件: |
哈希表:哈希冲突
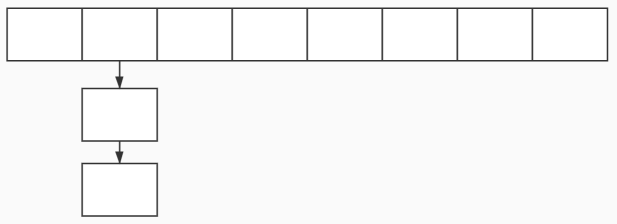
1 | 哈希表可以完成索引的存储,每次在添加索引的时候需要计算指定列的hash值,取模运算后计算出下标,将元素插入下标位置即可。 |
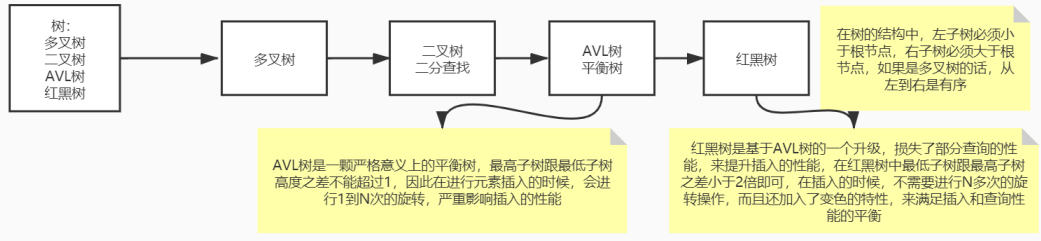
1 | 二叉树及其N多的变种都不能支撑索引,原因是数的深度无法控制或者插入数据的性能比较低。 |
Mysql索引系统
mysql索引数据结构 B+ Tree
1 | B+ Tree是在B Tree的基础上做的一种优化,变化如下: |
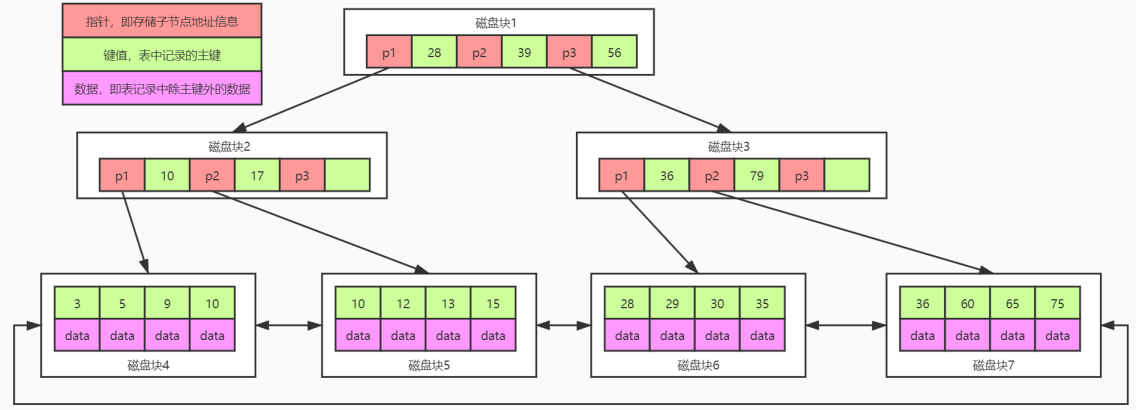
1 | 注意:在B+树上有两头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(数据节点)之间是一种链式环结构。 |

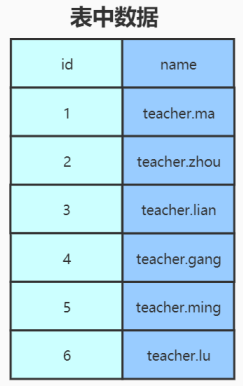
1 | 1. InnoDB是通过B+树结构对主键创建索引,然后叶子节点中存储记录。 |
mysql数据结构选择
hash表的索引格式

1
2
3缺点:
1. 利用hash存储的话需要将所有的数据文件添加到内存,比较耗费内存空间。
2. 如果所有的查询都是等值查询,那么hash确实很快。但是在企业或者实际工作环境中范围查找的数据更多,而不是等值查询,因此hash就不太适合了。二叉树和红黑树索引格式
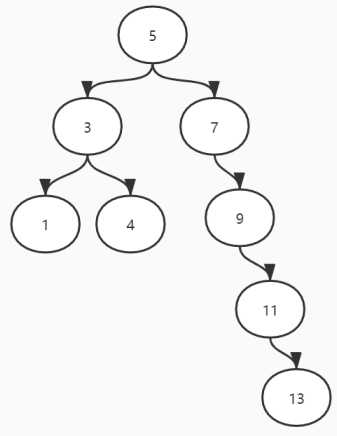
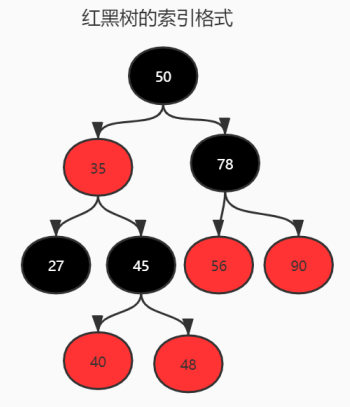
1
2
3二叉树:左子树上值小于它的根节点;右子树大于它的根节点;它的左右子树也分别为二叉排序树。
红黑树:一种平衡二叉树,红黑树的每个节点都有存储位表示节点的颜色,可以是红或者黑。每个节点都是红或者黑;根节点是黑;如果一个节点是红色的,则它的子节点必须是黑色的。
无论是二叉树还是红黑树,都会因为树的深度过深而造成IO次数变多,影响数据库读取的效率。B树的索引格式
1
2
3
4
5
6
7B树特点:
1. 所有键值分布在整颗树中
2. 搜索有可能在非叶子节点结束,在关键字全集内做一次查找,性能逼近二分查找。
3. 每个节点最多拥有m个子树
4. 根节点至少有2个子树
5. 分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
6. 所有叶子节点都在同一层,每个节点最多可以有m-1个key,并且以升序排列。
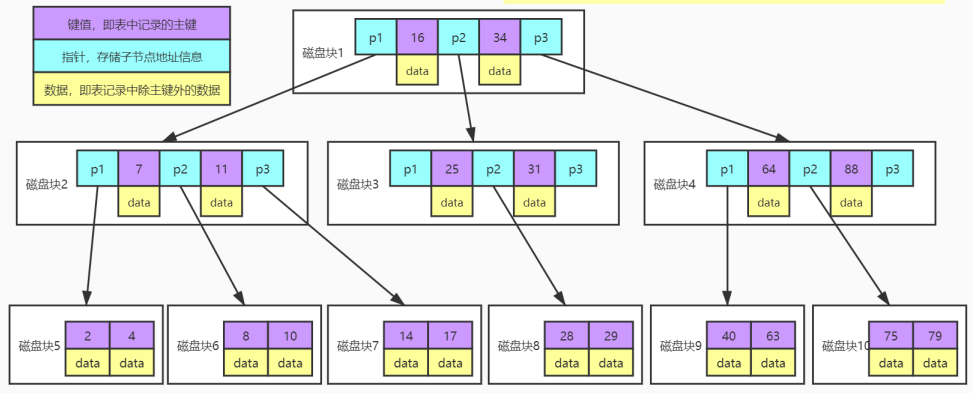

- B+树
1 | 1. 根节点只有1个,分支数量范围[2,m] |

