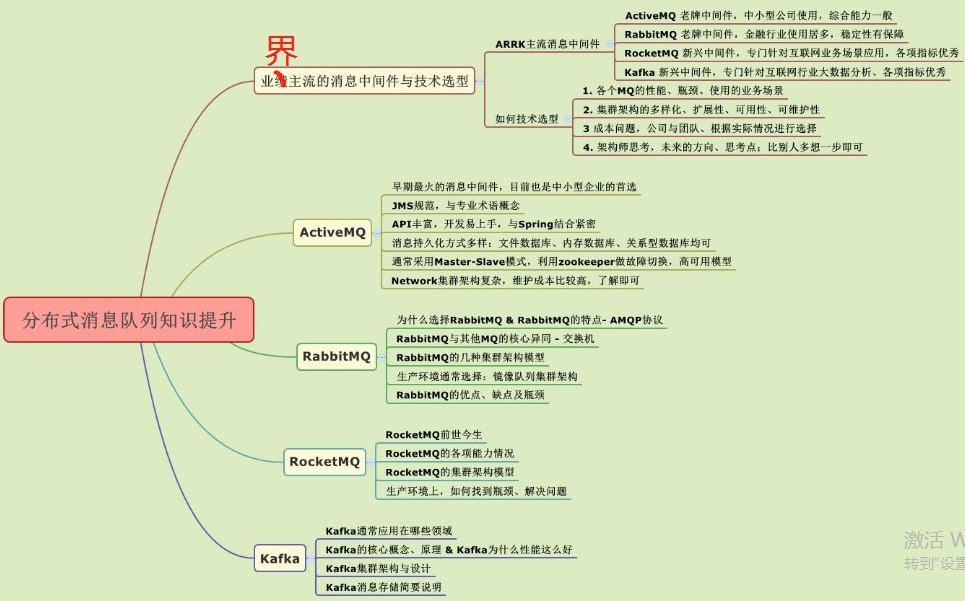
MQ
1 | 消息队列(Message Queue,简称MQ),本质是个队列,FIFO先入先出,只不过队列中存放的内容是message而已。 |
产生消息队列的原因
1 | 1.不同进程(process)之间传递消息时,两个进程之间耦合程度过高,改动一个进程,引发必须修改另一个进程. |
应用场景
- 服务解耦:系统之间拆分、隔离后的通信,之间的弱依赖可用消息中间件解耦
- 削峰填谷:秒杀大促,把流量高峰和低谷做一个均衡。把消息缓存然后慢速消费。
- 异步化缓冲:异步操作,只需做到最终一致性。
应用思考
- 生产端可靠性投递:消息不丢失,100%投递
- 消费端幂等:验证消息,防止消息被消费多次
其余点
- 高可用
- 低延迟
- 可靠性
- 堆积能力
- 可扩展性
技术选型
- 各个MQ的性能、优缺点、相应的业务场景
- 集群架构模式、分布式、可扩展性、高可用、可维护性
- 综合成本问题、集群规模、人员成本
- 未来的方向、规划、思考
ActiveMQ
古老而又神秘的消息中间件”ActiveMQ”
1 | 采用zookeeper做主备 |
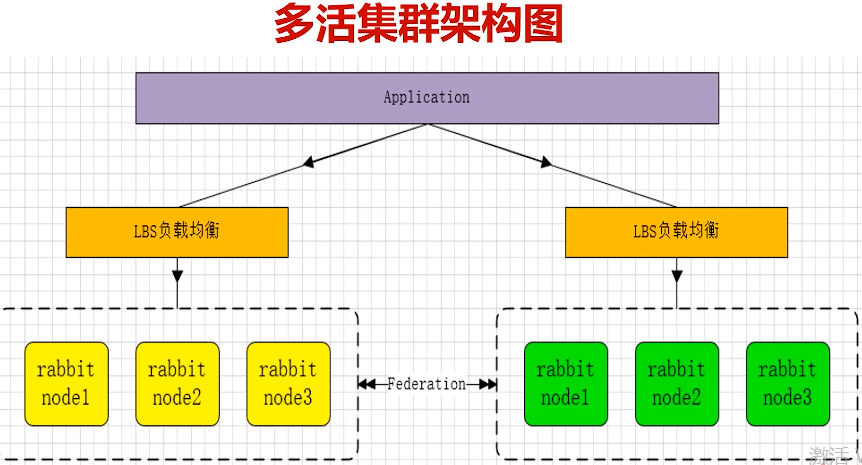
RabbitMQ集群架构模型与原理解析
RabbitMQ是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang语言来编写的,并且RabbitMQ是基于 AMQP协议的。
四种集群架构
- 主备模式:warren(兔子窝),主备方案(主挂了采用HAproxy做切换)
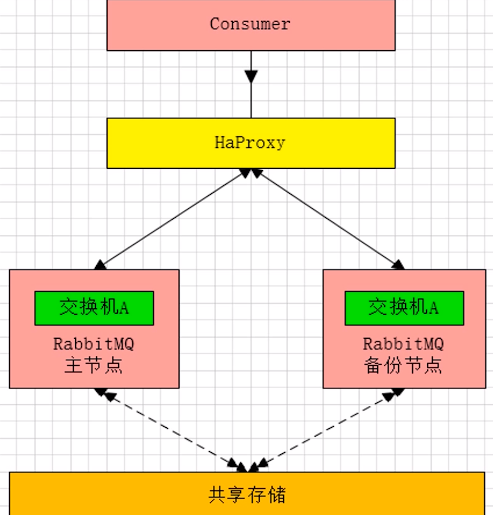
1 | # 主备模式-HAproxy配置 |
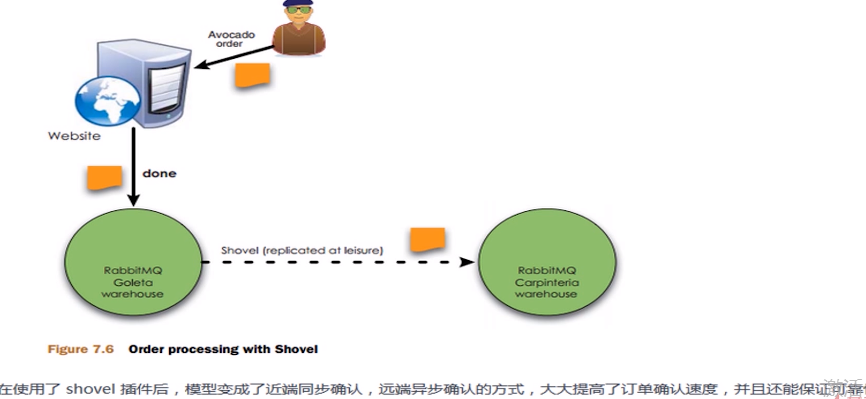
- 远程模式:远距离通信和复制,可以实现双活的一种模式,简称Shovel模式。(很少使用)
- 镜像模式:经典模式,mirror镜像模式,保障数据不丢失。实际工作中用的最多,并且实现集群非常简单,一般互联网公司都会使用这种镜像集群模式。
- Mirror镜像队列:高可靠(往每个节点发数据)、数据同步、奇数节点(3个就行,缺点无法横向扩展因为扩展的节点也只是备份前面的数据)
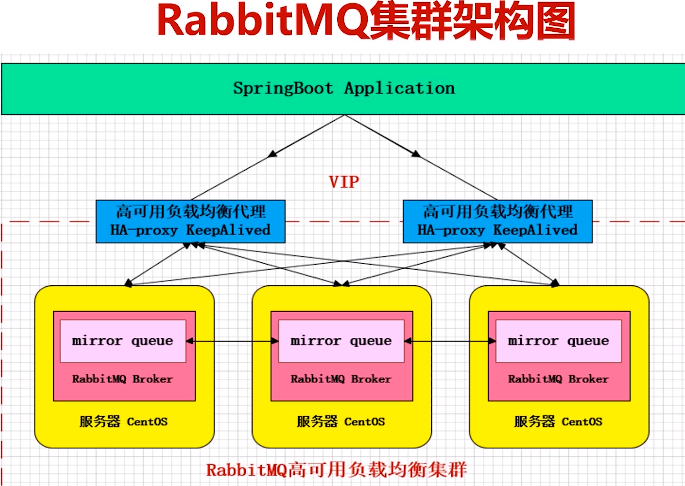
- Mirror镜像队列:高可靠(往每个节点发数据)、数据同步、奇数节点(3个就行,缺点无法横向扩展因为扩展的节点也只是备份前面的数据)
- 多活模式:实现异地数据复制的主流模式
- Federation:多活模式,federation插件
RocketMQ
RocketMQ是一款分布式、队列模型的消息中间件,由阿里巴巴自主研发的一款适用于高并发、高可靠性、海量数据场景的消息中间件。
Kafka
介绍
- kafka是Linkedln开源的分布式消息系统,目前归属于apache顶级项目
- 特点是基于pull的模式来处理消息消费,追求高吞吐量。最初目的就是用于日志收集和传输。
- 支持复制,不支持事务,对消息重复、丢失错误没有严格要求,适合大量数据的收集业务。比如日志。
特点
- 分布式:支持消息分区,topic下的patition
- 跨平台:java、python、php都支持
- 实时性:只要存储可以,不影响消息接收、堆积能力强
- 伸缩性
kafka高性能的原因
- 顺序写,page cache‘空中接力’(本质上把从磁盘中读取数据变为从内存中读取),高效读写
- 高性能、高吞吐
- 后台异步、主动flush
- IO预读策略
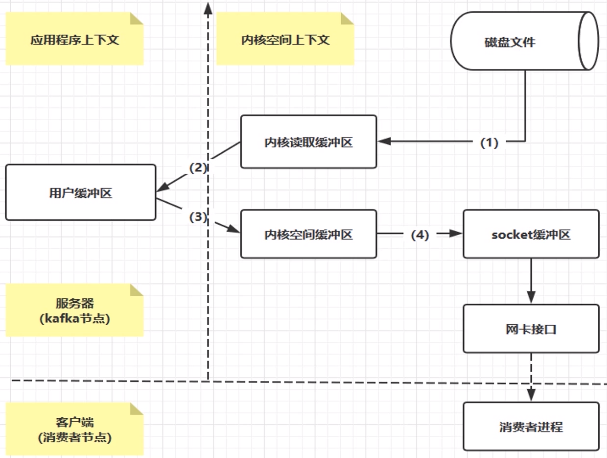
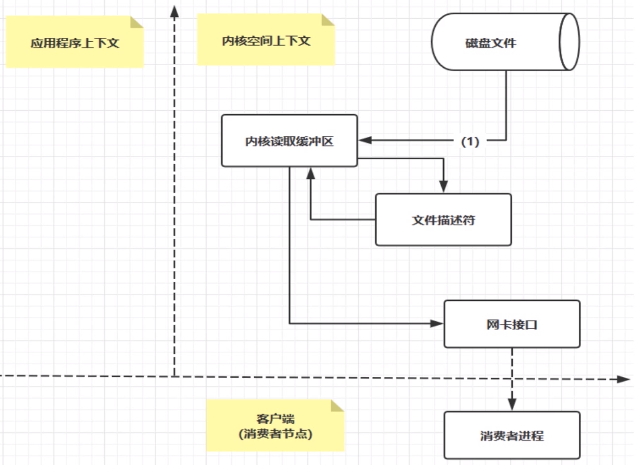
零拷贝
1 | mmap和sendFile这2个零拷贝 |
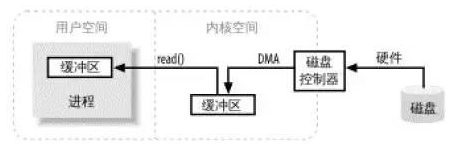
- 缓冲区
1
缓冲区是所有IO的基础,IO讲的无非就是把数据移进或移出缓冲区;进程执行IO操作,就是向操作系统发出请求。让它要么把缓冲区的数据排干(写),要么填充缓冲区(读)。
- 虚拟内存
1
2
3操作系统使用虚拟内存,虚拟地址取代物理地址好处如下:
1、一个以上的虚拟地址可以指向同一个物理内存地址
2、虚拟内存空间可大于实际可用的物理地址
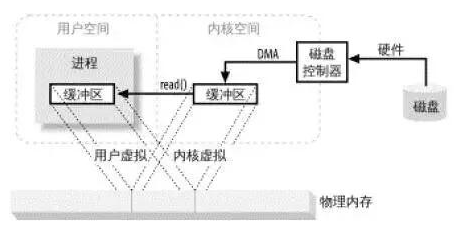
零拷贝的2种方式
- mmap+write方式
1
2
3使用mmap+write方式代替原来的read+write方式,mmap是一种内存映射文件的方法。
即将一个文件或其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一映射关系。
这样可以省掉原来内核read缓冲区copy数据到用户缓冲区,但是还是需要内核read缓冲区将数据copy到内核socket缓冲区。
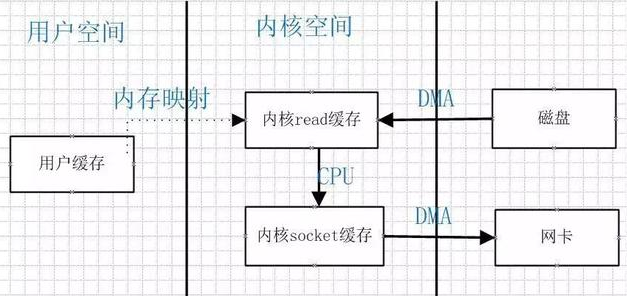
- sendfile方式
1
2
3简化通过网络在2个通道之间进行的数据传输过程,sendfile系统调用的引入,不仅减少了数据复制,还减少了上下文切换的次数。
数据传输只发生在内核空间,所以减少了一次上下文切换。
上下文切换(Context Switch),性质为环境切换。上下文切换,有时也称做进程切换或任务切换,是指CPU 从一个进程或线程切换到另一个进程或线程。
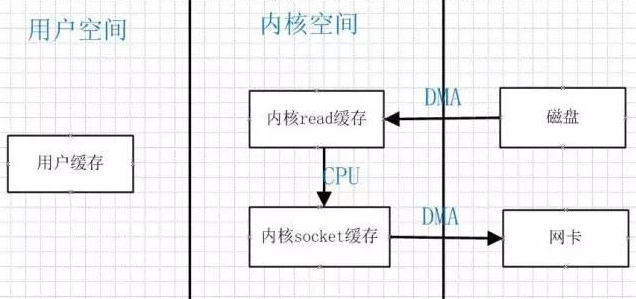
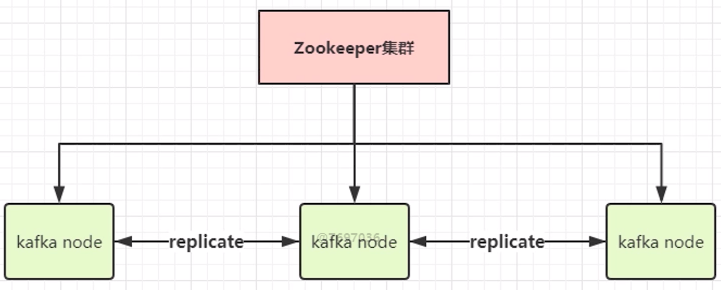
kafka集群模式
1 | 大部分做的内存的replicate; |
小结