分布式缓存Redis
1. 什么是Redis
- NoSQL
- 分布式缓存中间件
- key-value存储
- 提供海量的数据存储访问
- 所有数据放在内存中,读取速度非常快
- 非关系型,分布式、开源,支持水平扩展
2. 为什么使用内存缓存数据库
因为在我们的基础架构,我们的数据库一般都是第一节点(主从、MMM、MHA)
一遍导致数据库缓慢或宕机的都是查询导致的,update、delete,80%的SQL都是查询,如果能够将这80%SQL抽离到缓存中
Redis VS Memcache VS Ehcache
Ehcache
- 优点
- 基于Java开发的,被apache认证
- 基于JVM缓存的
- 简单、轻巧、方便(广泛的应用于hibernate,Mybatis)
- 缺点
- 不支持集群,单点
- 不支持分布式,存储容量不支持扩展
- 优点
Memcache
- 优点
- 简单的key-value存储
- 内存使用率比较高
- 支持多核多线程
- 缺点
- 无法容灾
- 无法持久化
- 优点
Redis
- 优点
- 丰富的数据结构
- 持久化:RDB、AOF
- 主从同步、故障转移(MySQL;主从)
- 内存数据库
- 缺点
- 单线程(不建议进行大数据量的存储)
- 单核(无法充分利用CPU多核性能,建议使用多实例)
- 优点
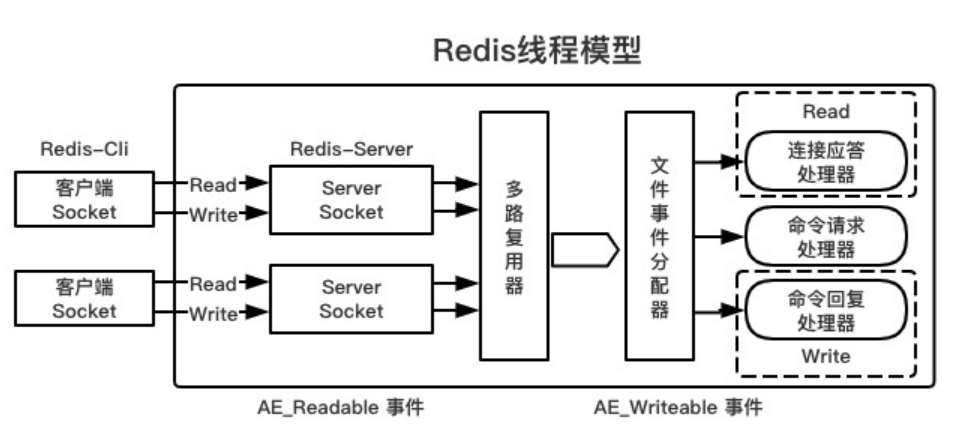
3、Redis作为单线程模型为什么效率还这么高?
1、纯内存访问:数据存放在内存中,内存的响应时间是100纳秒
2、非阻塞式的I/O操作:Redis采用epoll作为I/O多路复用技术的实现
3、采用单线程避免了不必要的上下文切换和竞争条件
什么是多路复用
如果你是一个老师,有30个学生做一道题,做完需要检查
1、按顺序检查,A,B,C
2、你创建30个分身,来检查30个结果
3、谁做完了谁举手,A,B、C,D
4. Redis服务安装及常用命令解析
1 | redis下载解压后 |
Redis五大数据类型
- string
1 | keys * #查看redis当前数据库所有的key-value,生成上不要用 |
- hash:对象
1 | 比如一个对象,这个一般在购物车中使用比较多 |
- list:栈
1 | 做管道通知 |
- set:集合
1 | sadd userSet 1 2 3 4 5 6 5 4 3 2 1 |
- zset:带有一个数据标签的集合
1 | zadd za1 10.99 apple 20.11 peach 40.89 banana 30.80 pear 50.79 cherry |
- GEO
1 | 在Redis3.2版本后才支持 |
5. 如何实现Redis数据持久化
如果我们Redis宕机内存中的数据没了,这个时候会发生什么?就会导致原来所有从Redis读的请求都去到DB了
确保我们重启完Redis还能将绝大部分的数据恢复进内存,怎么办?
是不是就要把内存 数据保存到磁盘便于恢复
5.1. RDB模式
就是每隔一段时间,定时保存,有点像MySQL中进程用到的mysqldump
默认redis就是开启RDB的
优势
- 每隔一段时间,全量备份
- 灾备简单,dump.rdb文件拷走就完了
- 在RDB备份的时候会fork一个新进程来操作,这就不影响提供读写进程的效率了
劣势
- 当备份后和故障间这段时间的数据无法保存
- 新fork的子进程会从父进程copy全部的内存数据(这个时候内存会瞬间膨胀两倍),会造成CPU和内存负担
- 由于是定时的备份,所以时效差
1 | after 900 sec (15 min) if at least 1 key changed |
注意的点:执行的备份命令是bgsave / 如果是使用save会阻塞redis的主进程
5.2. AOF模式
有点类似于mysql的binlog,他是把我们所有Redis的写操作命令记录下来了
AOF的特点
- 以日志的形式来记录用于的写操作
- 文件是以追加的方式而不是修改的方式
- redis的aof的恢复其实就是把文件从头到位执行一遍
优势
- 每秒数据的记录和操作
- aof的文件也是一个,所以当文件比较大的时候会触发aof文件重写机制进行文件压缩
劣势
- 同样的数据,AOF比RDB大的多
- aof同步的时候比rdb慢的多
- AOF重写的时候也会fork一个进程来操作
1 | AOF默认是关闭的,需要手工启用 |
重启redis不要使用kill进程的方法,这样会导致redis当前数据无法写入aof或rdb
使用客户端的shutdown来安全关闭redis
5.3. 持久化化文件是如何恢复的
- RDB文件只需要放在dir目录下我们的Redis会在重启后自动加载
- AOF文件也是只需要放在dir目录下我们的Redis会在重启后自动加载
- RDB和AOF不互相通信的
- AOF启用后,Redis优先选择AOF
如果线上没有开启aof,这个时候需要开启,不要进行配置修改后重启来生成aof文件
使用内部命令先开启config set appendonly yes
再去redis.conf里把appendonly 设置成yes
6. Redis内存管理之缓存过期机制
- 主动删除
- 默认1秒巡检10次定义了expire的key,如果过期就删除
- 可以设置redis.conf hz 10
- 惰性删除
- 如果你在访问的时候Redis发现这个key过期,就会返回nil并删除
- 是调用内部的expireIfNeeded()这个方法
如果超时比较久并且不超时的key比较多,redis内存满的怎么办?
这就Redis内存缓存的管理机制
1 | maxmemory <bytes> 限定主机的可写入最大内存阀值,还要给系统留一点 |
7. Redis高可用模型主从架构搭建
为什么要使用主从
- HA:高可用
- 高并发:读写分离
建议的主从结构,最好是1 master,2 slave
1 | 单机安装参考前面 |
但现在如何主机宕机了,redis是不会自动将master切换大其中一台slave上的
8. Redis故障转移哨兵模式分析
redis的sentinel哨兵
- 集群监控
- 消息通知
- 故障转移
- 配置中心
1 | 建议哨兵也搭建成集群方式,3台redis就搭建3个sentinel |
其他sentinel配置需要根据实际情况修改端口号即可
1 | 启动哨兵 |
1 | #单机设置 |
主从
- IP访问需要你自己去关联,你要访问哪个IP就走哪个IP
哨兵
- 做了一个主从的master故障转移操作
- slave的读操作还是要你自己指定
8. Redis分布式集群架构实战
刚刚我们学习的内容是不所有方式下,无论是主从(HA)还是单机,其实内存大小受限于一台服务器
如果这个master的内存快满了,你怎么扩展,如果扩展不了,redis何以称为分布式
10个key,A,B,C三个节点,A放了2个,B放了4个,C放了4个
集群的特性
- HA的:每个集群节点都是一组M/S(主/从),为什么是三组节点?3个节点,6个Redis
- 分布式的:
- 三个Master,三个slave
- 数据是根据crc16(key)mod 16384分摊到三个master节点上
Slot槽点
- Redis会在创建的时候生成16384个slot(固定数值,不变,可以理解为文件夹)
- 16384/3=5461(如果除不尽,会在一个master上多放一个slot)
- 每一个key在set时会hash个固定文件夹里,三个master的total才是完整数据
- 每个slot原则上可以放无数个key,依赖于内存大小
如果三台master内存不够需要扩展
- 只需要在集群中加入新的master
- 把现有master上的slot移动一部分给他就行

