zookeeper集群搭建
kafka集群是把状态保存在zookeeper中的,首先要搭建zookeeper集群。
1、安装jdk
1 | wget http://anchnet-script.oss-cn-shanghai.aliyuncs.com/oracle/jdk-8u171-linux-x64.rpm |
2、下载kafka安装包
1 | wget http://anchnet-script.oss-cn-shanghai.aliyuncs.com/kafka/kafka_2.12-1.1.0.tgz |
解压kafka
tar -zxvf kafka_2.12-1.1.0.tgz
mv kafka_2.12-1.1.0 kafka
3、配置zk集群
修改zookeeper.properties文件
直接使用kafka自带的zookeeper建立zk集群
1 | cd /data/kafka |
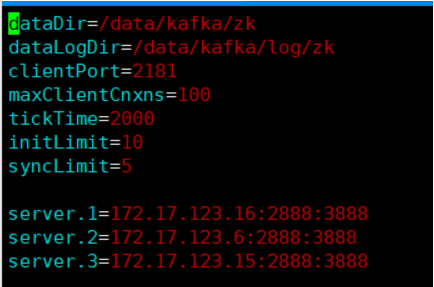
1 | #tickTime: |
创建myid文件
进入dataDir目录,将三台服务器上的myid文件分别写入1、2、3。
myid是zk集群用来发现彼此的标识,必须创建,且不能相同。
echo “1” > /data/kafka/zk/myid
echo “2” > /data/kafka/zk/myid
echo “3” > /data/kafka/zk/myid
注意项
zookeeper不会主动的清除旧的快照和日志文件,需要定期清理。
1 | #!/bin/bash |
4、启动zk服务
进入kafka目录,执行zookeeper命令
1 | cd /data/kafka |
没有报错,而且jps查看有zk进程就说明启动成功了。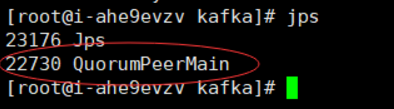
Kafka集群搭建
1、修改server.properties配置文件
vim conf/server.properties
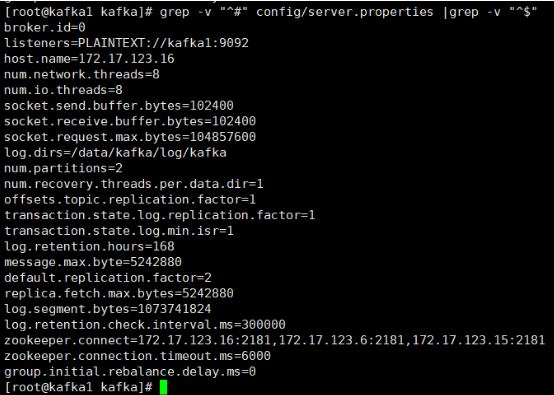
部分参数含义:
1 | 先每台设置host,listeners里要设置,否则后面消费消息会报错。 |
2、启动kafka集群
1 | nohup ./bin/kafka-server-start.sh config/server.properties > logs/kafka.log 2>&1 & |
执行jps检查
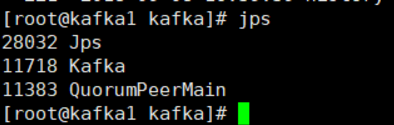
3、创建topic验证
1 | ./bin/kafka-topics.sh --create --zookeeper kafka1:2181,kafka2:2181,kafka3:2181 --replication-factor 2 --partitions 1 --topic test1 |
4、创建生产者和消费者
1 | #模拟客户端去发送消息,生产者 |
5、其他命令
1 | ./bin/kafka-topics.sh --list --zookeeper xxxx:2181 |
#删除kafka topic
./bin/kafka-topics.sh –delete –zookeeper xxxx:2181,xxxx:2181 –topic test1
#删除kafka相关数据目录
rm -rf /data/kafka/log/kafka/test*
#删除zookeeper相关路径
rm -rf /data/kafka/zk/test*
rm -rf /data/kafka/log/zk/test*
```

